データ解析コンペサイトのKaggleに登録して,試しにチュートリアルをやってみたので記事に上げておく.
Kaggleについての説明は色んなところでされているので細かくは行わないが,企業から出されたデータ解析のお題を解いて,賞金をもらったりデータサイエンス界隈での知名度を上げたりするのに使われるサイト.訓練データとテストデータが渡され,訓練データを元にモデリングしてテストデータで予測した結果を投稿するとその結果が返り,結果に基づいて順位が決まる,という流れになっているようだ.
Kaggleでは企業から出されるお題以外にもチュートリアルがいくつかあり,その中でも一番メジャーと思われるなものがこのTitanic問題である.タイタニック号の乗客についての情報から沈没事件の際の乗客の生死を予測する,というもの.
データの大きさも非常に小さく,予測もおそらくしやすいのでチュートリアルに良いのだろう.
今回はこのTitanic問題を試しにPythonで解いてみた,という内容.ただしデータの前処理などはほとんど行っていないので,最終的な精度もひどい (現時点で9564位/9790人).まあアルゴリズムの選定とかデータの解釈とかはこれからやるとして,とりあえずは提出したことを記録しておく.
今回のコードはjupyter notebookの形でまとめたものをこちらにあげてある.
データの中身
| 項目 | 説明 |
|---|---|
| PassengerID | 乗客ID |
| survival | 生死(0 = 死亡; 1 = 生存) |
| pclass | 乗客の社会階級(1 = 1st(High); 2 = 2nd(Middle); 3 = 3rd(Low)) |
| name | Name |
| sex | 性別 |
| age | 年齢 |
| sibsp | 乗船している夫婦、兄弟姉妹の数 |
| parch | 乗船している親、子供の数 |
| ticket | チケットNo |
| fare | 乗船料金 |
| cabin | 船室 |
| embarked | 乗船場所(C = Cherbourg; Q = Queenstown; S = Southampton) |
上記項目のうち,survivalをテストデータで予測する.すなわちsurvivalの属性は訓練データのみに入っている.
訓練データが891個,テストデータが418個ある.
分析環境
- 言語: Python3.6
- 環境: jupyter notebook
- アルゴリズム: Random forest
処理内容
必要なモジュールをインポート
import pandas as pd
import csv as csv
from sklearn.ensemble import RandomForestClassifier
訓練, テストデータをメモリへロード
# Load training and test data
train_df = pd.read_csv("../input/train.csv", header=0)
test_df = pd.read_csv("../input/test.csv", header=0)
訓練データの中身を確認
train_df.head(3)

性別の項目を数値 (ダミー変数) 化しておく.
しかし,Randomforestは決定木を複数個使ってモデル構築をするものだからダミー変数化はいらないのでは?と思ったのだが,この処理をしないと訓練時にエラーが出てしまう..
調べてみると,他の人もこの現象で悩んでいるようだ.
参考: python - Can sklearn random forest directly handle categorical features? - Stack Overflow
現状scikit-learnの仕様がこうなっているから従うしかないとのこと.
# Convert "Sex" to be a dummy variable (female = 0, Male = 1)
train_df["Sex"] = train_df["Sex"].map({"female": 0, "male": 1}).astype(int)
test_df["Sex"] = test_df["Sex"].map({"female": 0, "male": 1}).astype(int)
データの中には数値が入っていない項目を含むものもある (欠損値).このようなデータがいくつあるのかを調べる.
# 欠損値が含まれているデータの数がいくつあるかを項目ごとに調べる
train_df.isnull().sum()
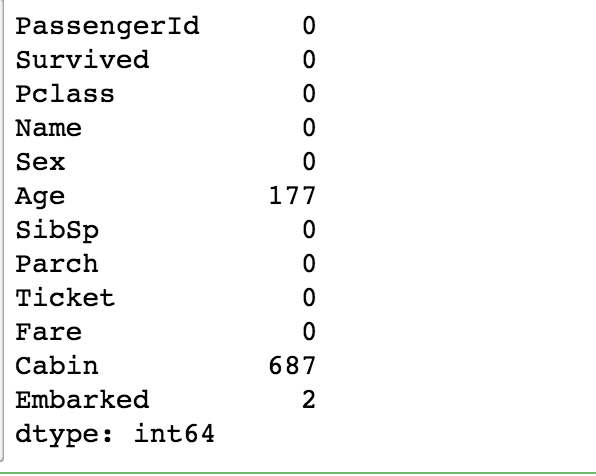
調べた結果,Ageに177件,Cabinに687件,Emberkedに2件の欠損値があることがわかった.訓練データのサンプル数が891件なので,データのうち687 / 891 = 約77%がCabinの項目が欠損していることがわかる.
欠損値は何か適当なデータで埋めてやったり,そもそもデータとして使わず捨てたりする場合があるようだ.どのようなデータが適当かはデータをよく見て決めないといけないのだろうが,今回はAgeの欠損値についてのみその中央値を入れておくことにする.
# XXX: 今回は暫定で単純に年齢のデータが欠損している部分は中央値を入れておく
train_df.Age.fillna(train_df.Age.dropna().median(), inplace=True)
test_df.Age.fillna(test_df.Age.dropna().median(), inplace=True)
で,諸々の属性は今回全部消してみる.精度を上げたければこの辺りの属性を見て,適切な前処理を行ってやる必要があるようだ.
# XXX: 今回はとにかく属性を削除しまくる
train_df = train_df.drop(["Name", "Ticket", "SibSp", "Parch", "Fare", "Cabin", "Embarked"], axis=1)
test_df = test_df.drop(["Name", "Ticket", "SibSp", "Parch", "Fare", "Cabin", "Embarked"], axis=1)
train_df.head(2)
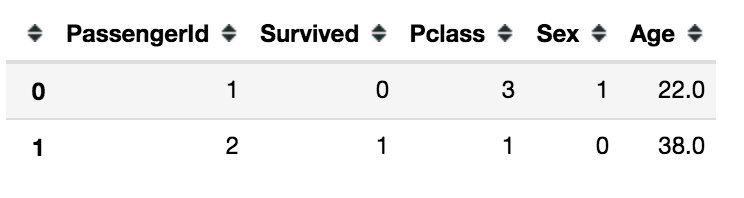
属性がほとんど無くなった.このうちPassengerIdはindexなので意味は無く,Survivedは予測したい属性.
訓練,テスト用のデータを準備する.
# Prepare data
X_train = train_df.drop(['PassengerId', 'Survived'], axis=1).values
y_train = train_df.Survived.values
X_test = test_df.drop('PassengerId', axis=1).values
モデル用のインスタンスを作成する.引数のn_estimatorsは決定木の数.
model = RandomForestClassifier(n_estimators=100)
モデルを訓練データを用いて訓練し,テストデータを用いて予測する.
# Predict with "Random Forest"
y_pred = model.fit(X_train, y_train).predict(X_test).astype(int)
テストデータに対して予測を行ったので,フォーマットして提出用のcsvを作成する.
(提出用フォーマットはKaggleの問題セットの中に入っている)
# Save prediction to csv file
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": y_pred
})
submission.to_csv('../output/submission.csv', index=False)
このやり方で予測した結果を提出した結果,精度は0.626だった.これからデータの前処理とかをして精度を高めていきたい.