google apiを使ってpythonでクローラを作ろうとしたら,意外と面倒だったのでメモしておく.
API keyを登録する
Google Could Platformにアクセスし,プロジェクトを作成してapi keyを登録する.
アクセスするとポップアップが立ち上がり, 利用規約に従うかどうかを聞かれるのでOKならYesを選択する.
次にページのヘッダーにあるSelect a projectの部分をクリックし,Create projectの+マークをクリック.
Project nameを適当につけて (画像はデフォルトのMy Project),Createでプロジェクトを作成する.
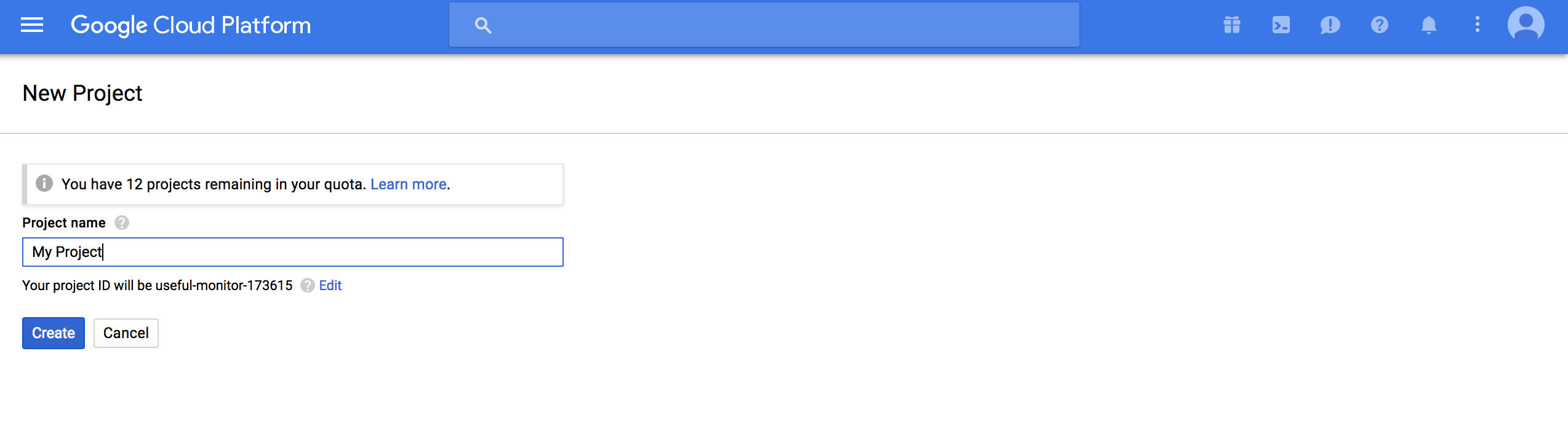
createしてしばらく待つと,プロジェクト内のダッシュボードが描画される.
次にAPI keyを作成する.
サイドバーのAPI ManagerからCredentialsをクリックし,Create credentials→API keyで作成できる. 作成時にAPI keyを使用するipの制限などができるRESTRICT KEYの設定があるので,必要ならば適宜設定を行う.
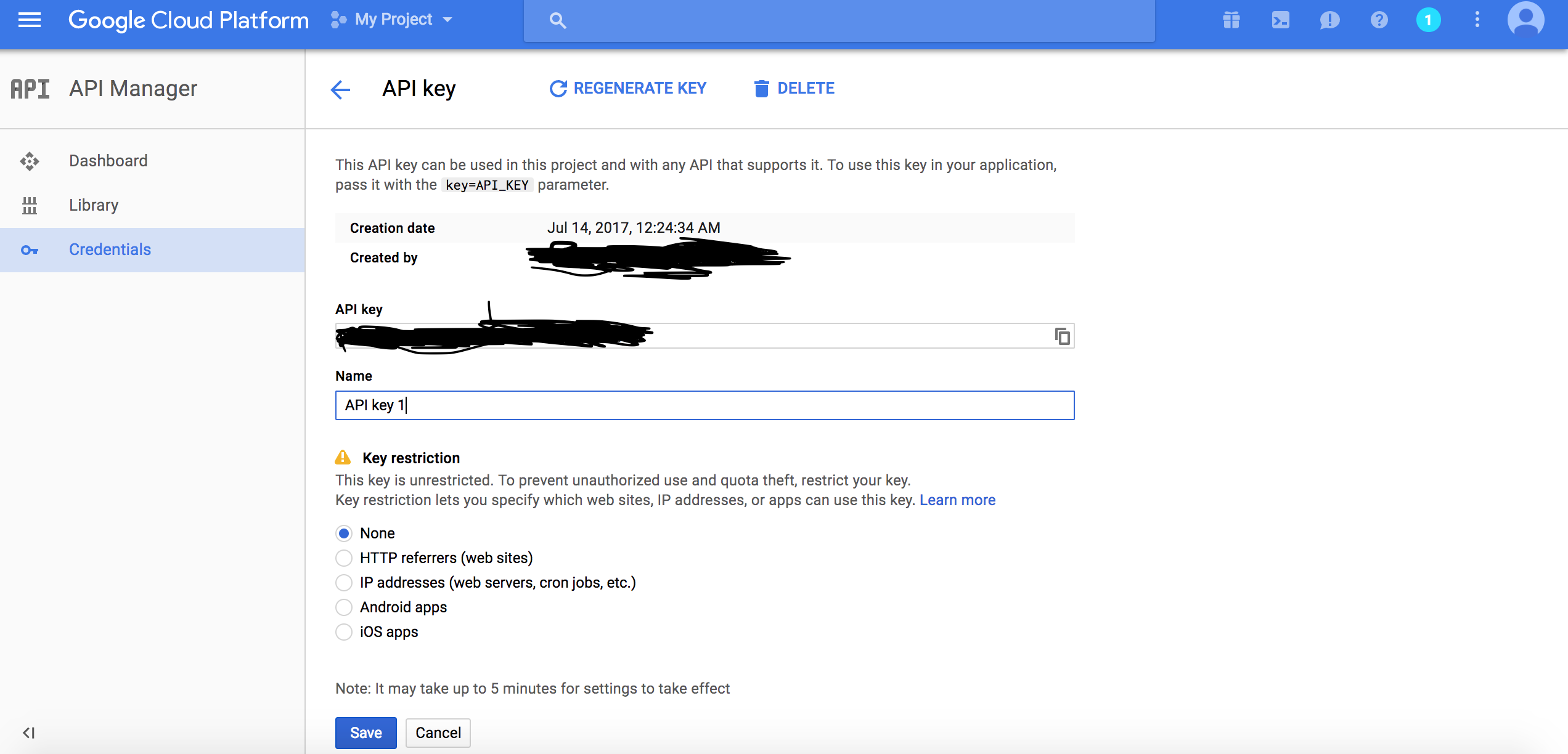 ※ 上の図はapi keyの設定画面.keyの使用に制限をかけていないと警告のため黄色い三角にビックリマークが表示されるようだ.
※ 上の図はapi keyの設定画面.keyの使用に制限をかけていないと警告のため黄色い三角にビックリマークが表示されるようだ.
Custom search engine IDを作成する
Custom Search - Create CSEからCustom search engine (CSE) を作成する.
Site to searchの部分にはとりあえずwww.example.comのExample Domainのページでも登録しておく.本来は検索をしたいサイトを登録するが,Webページ全体を検索対象としたいので無害そうなドメインを登録する.(別にCSE設定時に選択しなければよいだけだが)
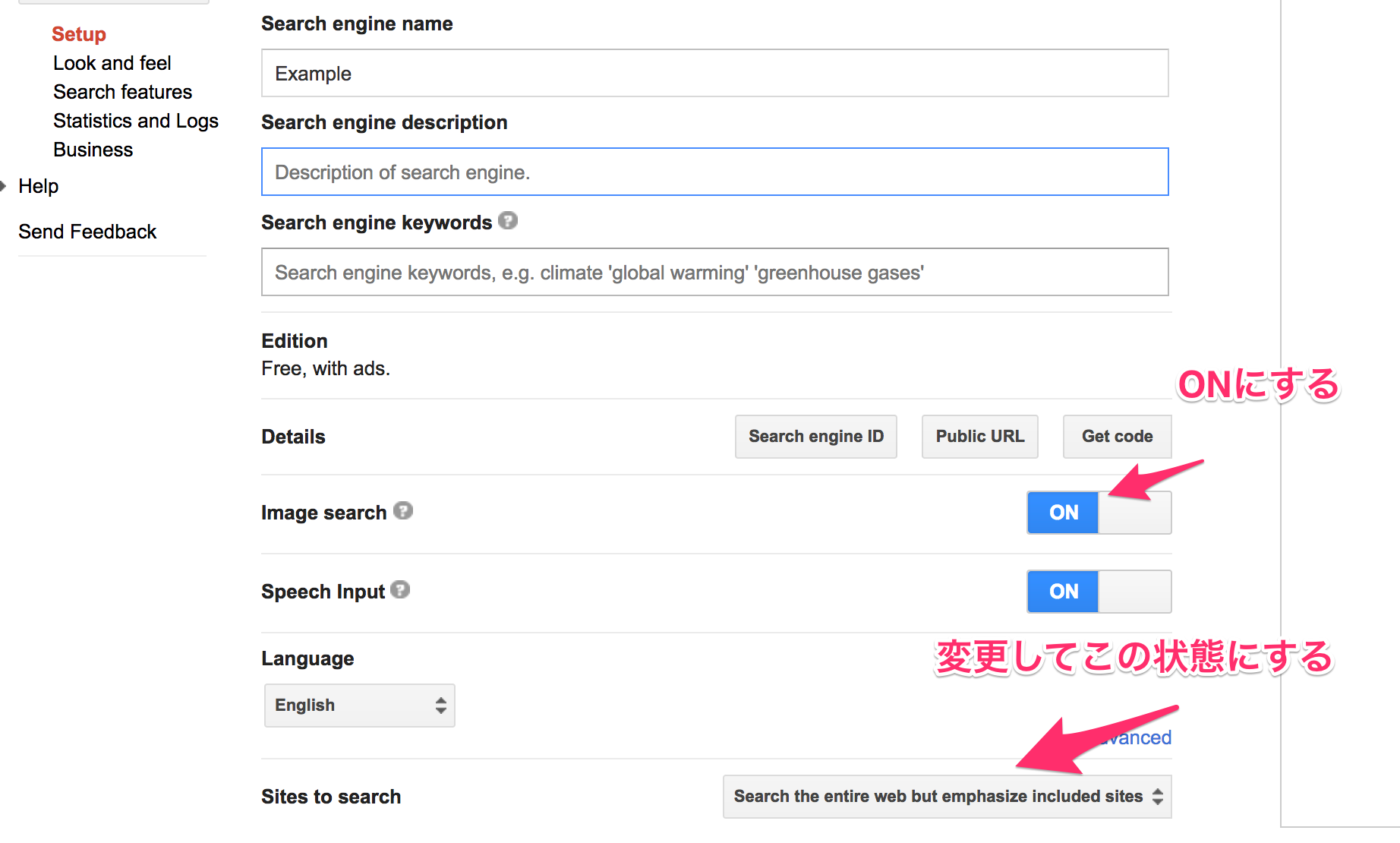
 search engineの名前を決めて,サイト下にあるCreateを押して登録.登録完了のページに遷移するので,そこでControl Panelのボタンをクリック.遷移先のDetailsのSearch engine IDをクリックしてIDの文字列を確認する.また,その下にあるImage searchのトグルをONにして, Site to searchのプルダウンメニューをSearch only included sitesからSearch the entire web but emphasize included sitesに変更する.
search engineの名前を決めて,サイト下にあるCreateを押して登録.登録完了のページに遷移するので,そこでControl Panelのボタンをクリック.遷移先のDetailsのSearch engine IDをクリックしてIDの文字列を確認する.また,その下にあるImage searchのトグルをONにして, Site to searchのプルダウンメニューをSearch only included sitesからSearch the entire web but emphasize included sitesに変更する.
画像検索用のスクリプトを組む
今回はこんな感じでpythonで書いた.
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
import argparse
import json
import os
import sys
from urllib.request import urlopen
from urllib.request import build_opener
from urllib.request import Request
from googleapiclient.discovery import build
# keywordの画像リンクを探索
def url_search(keyword, filetype, num):
"""Search url.
Args:
keyword(str): Keyword for search.
filetype(str): Filetype.
num(int): Number of search result to return.
"""
service = build("customsearch", "v1", developerKey=<YOUR_API_KEY>)
urls = []
offset = 1
limit = 10 # "num" parameters description: Valid values are integers between 1 and 10, inclusive.
if num < limit:
limit = num
while True:
res = service.cse().list(
cx=<YOUR_CSE_ID>,
searchType='image',
q=keyword,
num=limit,
start=offset,
fileType=filetype,
rights='cc_publicdomain cc_attribute cc_sharealike cc_noncommercial cc_nonderived',
).execute()
if 'items' in res:
urls += [item['link'] for item in res['items']]
offset += limit
if offset >= num:
break
return urls
def url_download(keyword, urls):
"""Download image resource from url."""
# Make directory if it does not exist.
if os.path.exists(keyword)==False:
os.mkdir(keyword)
print("Download Start...")
opener = build_opener()
# URLの数だけ画像DL
for i, url in enumerate(urls):
try:
fn, ext = os.path.splitext(url)
req = Request(url, headers={"User-Agent" : "Magic Browser"})
img_file = open(keyword + "/" + str(i) + ext, "wb")
img_file.write(opener.open(req).read())
img_file.close()
print("DL Image Link:" + str(i + 1))
except:
continue
def main(*args, **kwargs):
"""Main function."""
arg = args[0]
keyword = arg.keyword
filetype = arg.filetype
num = arg.num
urls = url_search(keyword, filetype, num=num)
url_download(keyword, urls)
print("End...")
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--keyword', '-k', type=str,
help='Retrieval keyword.')
parser.add_argument('--filetype', '-f', type=str,
help='Filetype')
parser.add_argument('--num', '-n', type=int, default=1,
help='Number of images you want to download.')
args = parser.parse_args()
sys.exit(main(args))上のスクリプトを自分のAPI keyとCSE idに書き換えて実行する.
実行例:
$ python get_image.py -k hoge -n 10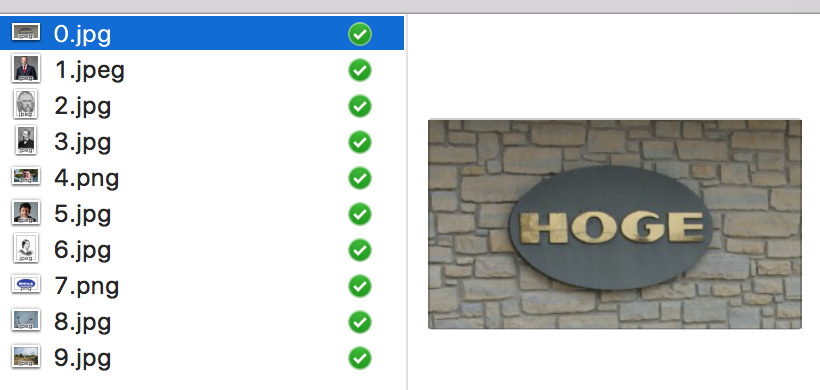
確かに画像が10枚ダウンロードされた.
今回使用したスクリプトでは検索のパラメータとして
res = service.cse().list(
cx=<YOUR_CSE_ID>,
searchType='image',
q=keyword,
num=limit,
start=offset,
fileType=filetype,
rights='cc_publicdomain cc_attribute cc_sharealike cc_noncommercial cc_nonderived',
).execute()のような感じで指定したが,パラメータの詳細は
$ python
>>> from googleapiclient.discovery import build
>>> service = build("customsearch", "v1", developerKey="hoge")
>>> help(service.cse().list)のようにして確認ができる.